Cross Attention Based Style Distribution for Controllable Person Image Synthesis
基于交叉注意力的风格分布用于可控的人物图像合成
ECCV-2022-8

图1. 左:给定源图像和目标位姿,我们的模型能够根据需要进行位姿传递并生成目标解析图。注意,对于目标解析图,我们只有一个训练阶段,没有独立生成。然而,我们的模型仍然通过基于交叉注意力的风格分布模块精确地合成它。右:我们的模型还通过显式控制源图像和参考图像的姿势和身体部位外观来实现虚拟试戴和头部(身份)交换。
摘要:可控人物图像合成任务通过对身体姿势和外观的明确控制实现了广泛的应用。在本文中,我们提出了一种基于交叉注意力的风格分布模块,该模块在源语义风格和目标姿态之间进行计算以进行姿势转移。该模块有意选择每个语义所代表的风格,并根据目标姿势分配它们。交叉注意力中的注意力矩阵表达了目标姿势和所有语义的源风格之间的动态相似性。因此,它可以用来路由源图像的颜色和纹理,并进一步受到目标解析图的约束,以达到更清晰的目标。同时,为了准确编码源外观,还添加了不同语义风格之间的自我关注。我们模型的有效性在姿势转移和虚拟试穿任务上得到了定量和定性验证。代码可在 https://github.com/xyzhuoo/CASD 获得。
引言 Inthoduction
最近,conditional GAN被用来将源样式转换为指定的目标姿态。生成器在其不同的层中将预定的样式与所需的姿态连接。例如,PATN 、HPT 、ADGAN 等通过插入多个结构相同的重复模块来组合风格和姿态特征。然而,这些模块通常由常用的操作组成,如Squeeze and Excite ( SE )或Adaptive Instance Normalization ( AdaIN ),缺乏将源风格与目标姿态对齐的能力。
相比之下,2D或3D变形应用于动机更明确的任务中。DefGAN , GFLA 和 Intr-Flow 通过估计源和目标姿态之间的对应关系来指导外观特征的传播。这些方法虽然生成了逼真的纹理,但在面对大变形时可能会产生明显的伪影。此外,往往需要多个训练阶段,第一阶段的不可靠流程限制了结果的质量。
本文旨在单个训练阶段更好地融合源图像和目标姿态特征。我们提出了一个简单的基于交叉注意力的风格分布( Cross Attention Based Style Distribution,CASD )模块来计算目标姿态和每个语义表示的源风格之间的关系,并将源语义风格分布到目标姿态。其基本思想是将目标姿态下的粗融合特征作为查询,要求来自不同语义组件的源风格作为键和值进行更新和细化。遵循ADGAN,每个语义区域内的外观由一个风格编码器描述,该编码器提取相应区域内的颜色和纹理(如头部、手臂或腿部等。)。风格特征由CASD块对目标姿态下的每个查询位置进行动态分配。特别地,来自每个语义的值被软加权并根据注意力矩阵加总在一起,从而与目标姿态匹配。可以进一步利用对齐后的特征来影响解码器的输入。
为了进一步提高合成质量,我们在CASD块内进行了一些特殊设计。
首先,为了将来自不同语义的样式紧密联系起来,自我关注在它们之间进行,使每个样式不再独立于其他样式。
其次,与注意力矩阵大小相同的另一种路由方案也被用于样式路由。它直接从目标位姿预测,无需与样式按键进行穷举比较。
第三,在注意力矩阵上加入来自目标解析图的额外约束,使注意力头(attention head)具有更明确的动机。
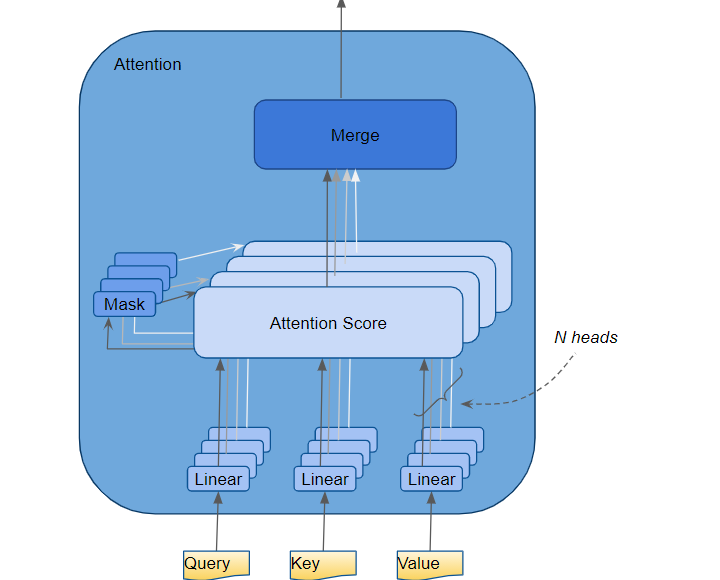
Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是从关注全部到关注重点
attention head:注意力头
在 Transformer 中,Attention 模块会并行重复计算多次。这些中的每一个都称为注意力头。 Attention 模块将其 Query、Key 和 Value 参数 N 向拆分,并通过单独的 Head 独立传递每个拆分。然后将所有这些类似的注意力计算组合在一起以产生最终的注意力分数。这称为多头注意力,它赋予 Transformer 更大的能力来为每个单词编码多种关系和细微差别。
这样,我们的注意力矩阵就代表了预测的目标解析图。此外,我们的模型还可以通过交换风格特征中的特定语义区域,实现基于参考图像的虚拟试穿和头部(身份)交换。图1展示了我们模型的一些应用。论文的贡献可以概括为以下几个方面。
贡献
- 我们提出了基于交叉注意力的风格分布( cross attention based style distribution,CASD )模块用于可控人物图像合成,该模块对每个语义所代表的源风格进行选择并分配到目标姿态。
- 我们有意加入了自我注意力来连接来自不同语义成分的风格,让模型预测基于目标姿态的注意力矩阵。此外,目标解析图被用作注意力矩阵的基本真值,在训练过程中赋予模型一个明显的对象。
- 我们可以通过显式控制身体姿势和外观来实现在图像处理中的应用,例如姿势转移、解析地图生成、虚拟试戴和头部(身份)交换。
- 在DeepFashion数据集上的大量实验验证了所提模型的有效性。特别地,从定量指标和用户研究两方面来看,合成质量有了很大的提高。
相关研究 Related work
以往的研究可以分为两阶段(或多阶段)或一阶段方法:
- 前者首先生成粗略图像或前景掩膜,然后将其作为输入送入第二级生成器进行细化。
GFLA 基于源图像、源和目标姿态预训练网络来估计2D流和遮挡掩码。然后,利用它们对源的局部面片进行扭曲,以匹配所需的位姿。
Liquid GAN 也采用三维模型引导前景区域内的几何变形。基于几何的方法虽然生成了逼真的纹理,但它们可能无法提取准确的运动,导致出现明显的伪影。
PISE 和SPGnet 在不做任何变形操作的情况下,给定源掩码、源姿态和目标姿态作为第一阶段的输入,合成目标解析图。然后在第二阶段利用它们生成图像。
这些工作表明,目标位姿下的解析图具有用于位姿传递的潜力。
- 与两阶段方法相比,单阶段模型训练负担较轻。
DefGAN 显式地计算源和目标块之间的局部2D仿射变换,并应用变形将源特征对齐到目标位姿。
PATN 提出了一个重复的姿态注意力模块,由类似SE - Net的计算组成,用于组合来自外观和姿态的特征。
ADGAN使用纹理编码器提取每个语义内的风格向量,并将其赋予多个AdaIN残差块来合成目标图像。
Xing GAN 提出了两种类型的交叉注意力块,从目标姿态和源外观两个方向重复融合特征。这些模型虽然设计了姿态和外观风格的融合块,但缺乏将源外观与目标姿态对齐的操作。
CoCosNet 通过注意力操作计算跨域图像之间的稠密对应关系。然而,每个目标位置只与源图像的局部块相关,这意味着相关矩阵应该是稀疏矩阵,而稠密的相关矩阵会导致二次内存消耗。
我们的模型通过一个高效的CASD块来处理这个问题。
Attention和Transformer模块首先出现在NLP中,它们以动态的方式扩大感受野。非局部网络是其在图像领域的首次尝试。由于其有效性,该方案在图像分类、目标检测和语义分割等任务中越来越受欢迎。它基本上有两种不同的方式:自我关注和交叉关注。自注意力从相同的token集合中投影查询、键和值,而交叉注意力通常从一个集合中获取键和值,从另一个集合中获取查询。然后计算过程变得相同,度量查询和键之间的相似性,形成一个注意力矩阵,用于加权值来更新查询token。基于重复注意力模块,可以构建多级transformer。值得注意的是,添加MLP ( FFN )和阶段之间的残差连接是至关重要的,并成为一个设计例程。
方法 Method

图2 .我们提出的生成器的概述架构。有单独的姿态和风格编码器,它们的输出$F_p$和$F_s$被AdaIN ResBlks和基于交叉注意力的风格分布( Cross Attention based Style Distribution,CASD )块融合,并将姿态对齐的特征Fps作为输出。然后,将相同的Fps通过AFN ResBlks适配到解码器。关键组件CASD Block由自注意力和交叉注意力组成,也可以输出预测的目标解析图( St .
概述框架 Overview Framework
给定一幅源图像$I_s$在位姿$P_s$下,我们的目标是合成一幅高保真图像( $\hat I_t$在不同目标位姿$P_t$下)。图2展示了所提出的生成模型的概述。它由姿态编码器Ep、语义区域风格编码器Es和解码器Dec组成。此外,还有几个基于交叉注意力的样式分布(CASD)块,它们是我们生成器中的关键组件。在注意力前后,有多个类似的AdaIN残差块和Aligned Feature Normalization ( AFN )残差块。前者粗略地将源风格适应于目标姿态,后者则将来自CASD块的姿态对齐特征融入解码器。两者都是可学习的,改变了各自影响层的特征统计量。
如图2所示,期望的$P_t$直接作为编码器Ep的输入,它描述了人体关键点位置。对于每个点,我们制作了一个带有预定义标准差的单通道热图来描述其位置。除个别点外,为了更好地对位姿结构进行建模,在选取的点之间额外采用直线。共有18个点和12条线,所以$P_t\in \R ^{H \times W \times 30}$。为了便于从$I_s$中准确提取风格,我们遵循文献[ 23 ]中的策略,利用源解析图$S_s∈\R^{H \times W \times N_s}$将整幅图像分割成区域,使Es独立编码不同语义的风格。
- Men, Y., Mao, Y., Jiang, Y., Ma, W.Y., Lian, Z.: Controllable person image synthesis with attribute-decomposed gan. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5084–5093 (2020)
$N_s$是解析图中语义的总数。在训练过程中,利用真实参考图像$I_t$及其对应的解析图$S_t$。注意,$F_p\in \R^{H \times W \times C}$和$F_s\in \R^{N_s × 1 × 1 × C}$分别表示来自Ep和Es的姿态和风格特征。它们被CASD块所利用,其细节在下一节中介绍。此外,CASD块被多次重复,例如两次,逐渐完成Fp和Fs之间的融合,形成更好的对齐特征Fps。最后,将Fps从边分支给予AFN以发挥其作用。此外,我们的CASD块还可以通过约束交叉注意力矩阵输出预测的目标解析图( $\hat S_t$ )。
前、后注意风格注入 Pre- and Post-Attention Style injection
由于源风格$F^i_s\in \R^{1 \times 1 \times C}$由共享权重编码器Es独立编码,其中i = 1,2,· · ·,$N_s$为语义索引,它们可能不适合一起进行风格注入。因此,我们首先通过一个MLP将来自不同语义区域的$F^i_s$进行融合,并将结果交给AdaIN ResBlks将$F_s$与$F_p$进行粗略融合,指定反映目标姿态$P_t$的粗略融合$F_{crs}$,然后将其作为CASD块中的查询参与交叉注意力。
MLP:多层感知器
经过CASD块后,我们得到了明显优于$F_{crs}$的Fps,并且适合被Dec利用。我们没有将$F_{ps}$直接赋予Dec,而是设计了一个AFN ResBlks将其作为条件特征。在块内,首先预测一个偏移量$\beta$和一个缩放因子$\gamma$。然后,通过AFN发挥作用,AFN根据$\beta$和$\gamma$进行条件归一化。注意:$F_{ps},\beta和\gamma$的大小相同。
基于交叉注意力的风格分布块 Cross Attention based Style Distribution Block

图3 .基于交叉注意力的风格分布( CASD )块示意图。在右边,对源风格特征$F_s$进行自注意力,将更新后的$F'_s$作为输出。在左边,在粗对齐的特征$F_{crs}$和更新的风格特征$F'_s$之间计算交叉注意力。姿态$F_p$也加入了交叉注意力。并通过约束交叉注意力矩阵AM,生成预测目标解析图( $\hat S_t$ )。注意$\alpha _{1-3}$表示可学习的缩放因子。
CASD块的计算包括两个阶段,分别为自注意力阶段和交叉注意力阶段,如图3所示。两类注意力依次进行,根据目标姿态特征$F_p$共同对齐源风格$F_s$。我们在以下两节中对它们进行描述。
对于风格特征的自注意力。自注意力在$F^i_s$之间进行,使得每个特定语义的$F^i_s$与其他$F^j_s$连接,其中$j \neq i$。我们简化了Transformer中自注意力模块的经典设计[ 33 ]。传统上,有三个可学习的投影头$W_Q,W_K和W_V$,它们的形状相同,$W_Q,W_K,W_V\in \R^{C \times C}$。
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need. In: Advances in neural information processing systems. pp. 5998–6008 (2017)
这些头负责将输入的tokens $F_s$映射为query Q、key K和value V。在我们的应用中,为了减少可学习的参数,我们省略了$W_Q$和$W_K$,直接使用$F_s$作为query 和key。然而,我们保持$W_V$,它在$F_s$的同一维度上产生$V∈RNs × C$。计算更新风格特征$F^{att}_ s$的自注意力可以归纳为式( 1 )。
$$ F^{att}_s = Attention(Q,K,V)=Softmax(QK^T/\sqrt C)V \tag{1} \\ Q=F_s,\;K=F_s,\; V=F_sW_V $$
这里的attention模块实质上是比较不同语义风格的相似性,使$F_s$中的每个$F^i_s$从其他风格标记$F^j_s$中吸收信息。注意,我们也遵循transformer中常见的设计。特别地,$F_s$和$F^{att}_s$之间存在一个残差连接,因此将它们相加,并赋予后面的层。最终风格用$F'_s$表示,如图3右图所示。此外,与传统的transformer不同,我们使用文献[ 39 ]中提出的层实例归一化( SW-LIN )来代替LN以更好地合成。
- Xu, W., Long, C., Wang, R., Wang, G.: Drb-gan: A dynamic resblock generative adversarial network for artistic style transfer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6383–6392 (2021)
交叉注意交叉注意力模块进一步将源风格$F'_s$适应到所需的姿态中,如图3左侧所示。这种关注是跨不同领域进行的,从AdaIN结果输出的粗融合$F_{crs}$和风格特征$F'_s$之间。因此,不同于以往的自注意力,其结果$F_{ps}$具有空间维度,实际上反映了在预定的姿态下如何分配源风格。在该模块中,来自AdaIN ResBlks的$F_{crs}$被视为 queries Q。每一个都是一个C-dim向量。$F'_s$提供了与Q比较的key K和软选择的value V。
这里我们对常见的注意力计算进行聚合,如式( 2 )所示。$F^{att}_{ps} \in \R^{H \times W \times C}$为注意后查询的更新量,与$F_{crs}$大小相同。
$$ \begin{gathered} F^{att}_{ps}&=Attention(Q,F_p,K,V)=AM.V \\ &=(Softmax(\frac{QK^T}{\sqrt{C}}+Proj(F_p)))V \end{gathered}\tag{2} $$
注意到我们设定$Q = F_{crs}W_Q,K = F'_sW_K,V = F'_sW_V$,所以注意实际上是将特征$F_{crs}$和来源风格$F'_s$结合起来。在式( 2 )中,括号中的第一项表示正则注意力矩阵,它穷举计算每个Q - K对之间的相似性。它的形状为$H \times W \times N_s$,并为每个位置确定可能的归属语义。由于存在投影头$W_Q$和$W_K$来调整query和key,注意力矩阵是完全动态的,不利于模型收敛。我们的解决方案是添加与第一项形状相同的第二项,形成增强注意力矩阵 AM ,并让它参与value路由。$Proj(.)$是一个线性投影头,它直接输出一个仅基于$F_p$的路由方案。因此,这意味着在给定编码的位姿特征$F_p$的情况下,模型能够预测每个位置的目标解析图。最近的一些工作如SPGNet 或PISE有单独的训练阶段,根据需要的姿态生成目标解析图。我们的模型具有相似的意图,但只需要单一的训练阶段,更加方便。在下一节中,我们对注意力矩阵添加了一个约束来生成预测的目标解析图。
在式( 2 )中的交叉注意力之后,我们遵循Transformer中的惯例,首先将$F^{att }_{ps}$和$F_p$进行元素求和,然后将结果交给FFN,从而得到一个更好的姿态特征$F_{ps}$,它结合了下一阶段的源样式。
学习目标 Learning Objectives
与前面的方法[ 50、23]类似,我们采用对抗损失$L_{adv}$、重构损失$L_{rec}$、感知损失$L_{perc}$和上下文损失$L_{CX}$作为学习目标。此外,我们还采用了注意力矩阵交叉熵损失$L_{AMCE}$和LPIPS损失$L_{LPIPS}$来训练我们的模型。完整的学习目标如式( 3 )所示。
$$ \begin{gathered} L_{full}=\lambda_{adv}L_{adv}+\lambda_{rec}L_{rec}+\lambda_{perc}L_{perc}+\lambda_{CX}L_{CX}\\ +\lambda_{AMCE}L_{AMCE}+\lambda_{LPIPS}L_{LPIPS } \end{gathered}\tag{3} $$
其中$\lambda_{adv},\lambda_{rec},\lambda_{perc},\lambda_{CX},\lambda_{AMCE}和\lambda_{LPIPS}$是控制这些目标相对重要性的超参数.具体如下。
注意力矩阵交叉熵损失。 为了用明显的对象训练我们的模型,我们采用交叉熵损失来约束靠近目标解析图$S_t$的注意力矩阵AM,定义为:
$$ L_{AMCE}=-\sum^H_{i=1}\sum^W_{j=1}S_t(i,j,c)log(AM(i,j,c))\tag{4} $$
其中,i,j表示空间维度在注意力矩阵AM中的位置,c表示语义维度在注意力矩阵AM中的位置。通过在训练过程中使用这种损失,我们的模型可以在单个阶段生成预测的目标解析图。
对抗性损失。 我们采用了姿态判别器$D_p$和风格判别器$D_s$来帮助G在对抗训练中产生更真实的结果。具体来说,将真实位姿对$(P_t , I_t)$和虚假位姿对$( P_t ,\hat I_t)$馈入$D_p$进行位姿一致性。同时,将真实图像对$(I_s,I_t)$和虚假图像对$(I_s, \hat I_t)$输入$D_s$进行风格一致性处理。注意,两个判别器都以端到端的方式与G进行训练,相互促进。
$$ \begin{aligned} L_{adv}= 𝔼 _{I_s,I_t,P_s}[log(D_s(I_s,I_t)·D_p(P_t,I_t))]\\ +𝔼 _{I_s,P_t}[log(1-D_s(I_s,G(I_s,P_t)))\\ ·(1-D_p(P_t,G(I_s,P_t)))] \end{aligned}\tag{5} $$
重建和知觉损失。重建损失$L_{rec}$用来激励生成的图像$\hat I_t $在像素级别上与真实图像$I_t$相似,即$L_{rec} \lVert\hat I_t-I_t\rVert_1$。感知损失计算从预训练的VGG - 19网络中提取的特征之间的$L_1$距离。可写为$L_{perc} = \sum_i \lVert \phi_i(\hat I_t)-\phi_i(I_t)\rVert_1$,其中$\phi_i$为预训练VGG - 19网络第i层的特征图。
语境损失。我们还采用了文献[ 22 ]中首次提出的上下文损失,旨在衡量两幅非对齐图像之间的相似性,用于图像变换。其计算公式为式( 6 )。
- Mechrez, R., Talmi, I., Zelnik-Manor, L.: The contextual loss for image transformation with non-aligned data. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 768–783 (2018)
$$ L_{CX}=-log(CX(F^l(\hat I_t),F^l(I_t)))\tag{6} $$
这里 $F^l(\hat I_t)$ 和 $F^l(I_t)$ 分别表示从图像$ \hat I_t$ 和 $I_t $的预训练 VGG-19 的 $l = relu\{3 2, 4 2\}$ 层提取的特征,CX 表示特征之间的余弦相似度度量。
LPIPS Loss.为了减少失真和学习感知相似性,我们集成了LPIPS损失,与更标准的感知损失相比,LPIPS损失可以更好地保持图像质量:
$$ L_{LPIPS}=\lVert F(\hat I_t)-F(I_t)\rVert_2\tag{7} $$
其中$F ( · )$表示从预训练的VGG - 16网络中提取的感知特征。
实验 Experiments
实验装置 Experimental Setup
Dataset
我们在DeepFashion (In-shop Clothes Retrieval Benchmark) 上进行了实验,该数据集包含52,712张高质量的人物图像,分辨率为256 × 256。遵循文献[ 50 ]相同的数据配置,我们将该数据集拆分为训练和测试子集,分别有101,966和8,570对。此外,我们使用从人类解析器获得的分割掩码[ 8 ]。注意训练集和测试集的人员ID不重叠。
- Zhu, Z., Huang, T., Shi, B., Yu, M., Wang, B., Bai, X.: Progressive pose attention transfer for person image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2347–2356 (2019)
- Gong, K., Liang, X., Zhang, D., Shen, X., Lin, L.: Look into person: Self-supervised structure-sensitive learning and a new benchmark for human parsing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 932–940 (2017)
评价指标。我们使用SSIM、FID、LPIPS和PSNR四个指标进行评估。在已知真值的图像生成任务中,峰值信噪比( PSNR )和结构相似性指标( SSIM )是最常用的。前者利用均方误差给出整体评价,后者计算全局方差和均值来评估结构相似性。同时,学习的感知图像块相似度( LPIPS )是计算感知域中各代与真实图像之间距离的另一种度量。此外,Frechet起始距离( FID )被用来衡量生成图像的真实感。计算生成数据和真实数据分布之间的Wasserstein-2距离。
实施细则。我们采用Adam优化器,$\beta_1 = 0.5,\beta_2 = 0.999$,使用与其他工作相同的epochs来训练我们的模型大约330k次迭代。学习目标的权重设置为:$\lambda_{AMCE} = 0.1,\lambda_{LPIPS} = 1,\lambda_{rec} = 1,\lambda_{perc} = 1,\lambda_{adv} = 5和\lambda_{CX} = 0.1,$不进行调整。语义部分的数量$N_s = 8$,包括背景、裤子、头发、手套、脸、衣服、胳膊和腿等普通语义。此外,学习率初始设置为0.001,经过115k次迭代后线性衰减为0。按照上述配置,我们交替优化生成器和两个判别器。如第3节所述,我们为姿态转移任务训练模型,训练收敛后,我们对所有任务使用相同的训练模型,例如,姿态转移、虚拟试戴、头部(身份)交换和解析地图生成。
姿态迁移 Pose Transfer
在本节中,我们将我们的方法与几种先进的方法进行比较,包括PATN 、GFLA 、ADGAN、PISE 、SPGNet 和CoCosNet。通过定量和定性结果以及用户研究验证了本文方法的有效性。所有的结果都是直接使用源代码和作者发表的训练好的模型得到的。由于CoCosNet使用了不同的训练/测试分割,我们在测试集上直接使用其训练好的模型。
定量比较。定量结果列于表1。值得注意的是,与其他方法相比,我们的方法在大多数指标上取得了最好的性能,这可以归因于提出的CASD块。

见表1。图像质量和用户研究指标的比较。SSIM、FID、LPIPS和PSNR是合成图像的量化指标。R2G、G2R和Jab是根据用户反馈计算得到的指标。

图4 .我们的方法与其他先进方法的定性比较。目标真值和每个模型的合成结果以行列出。
定性比较。在图4中,我们比较了不同方法生成的结果。可以观察到我们的方法产生了更加真实合理的结果(例如,第二、第三和倒数第二行)。更重要的是,我们的模型可以很好地保留源图像(例如,第四和最后一行)中的细节信息。此外,即使目标姿态是复杂的(例如,第一行),我们的方法仍然可以精确生成。
用户研究虽然定量和定性比较都可以从不同方面评估生成结果的性能,但人体姿态迁移任务往往是面向用户的。因此,我们与30名志愿者进行了用户研究,以评估人类感知方面的性能。用户研究由两部分组成。( 1 )与"真实"的比较。根据文献[ 19 ],我们从测试集中随机选择30张真实图像和30张生成图像并进行洗牌。志愿者需要在一秒内判断给定的图像是真还是假。( 2 )与其他方法相比,我们向志愿者展示了随机选取的30幅图像对,这些图像对包括源图像、目标姿态、ground-truth和通过我们的方法和基线生成的图像。要求志愿者选择相对于源图像和ground-truth最真实合理的图像。注意,为了公平起见,我们对所有生成的图像进行了洗牌。结果见表1右侧部分。这里我们采用三个度量指标,即R2G:真实图像作为生成图像的百分比;G2R:生成图像作为真实图像的百分比;Jab:所有模型中被判定为最佳的图像百分比。这三个指标的值越高意味着性能越好。我们可以观察到我们的模型取得了最好的结果,特别是在Jab上比第二个最好的模型高出约11 %。
消融研究 Ablation Study
在本节中,我们进行消融研究来进一步验证我们的假设并评估模型中每个成分的贡献。我们通过从全模型$( w / o \;{self-attn} , w / o\;AM_p , w / o L_{AMCE})$中交替移除一个特定成分来实现3种变体。
W/o self-attn.该模型去除CASD块中的自注意力,仅使用交叉注意力,直接将$F_s$作为Key和Value反馈到交叉注意力中。
W/o $AM_p$.该模型去除了式( 2 )中CASD块中的$AM_p = Proj ( Q )$,从而不会让模型根据目标位姿预测注意力矩阵。
W/o$ L_{AMCE}$.该模型没有采用式( 4 )中定义的$L_{AMCE}$损失进行训练,因此在交叉注意过程中不能被目标解析图明确引导。
Full model.它包含了所有组件,并在所有定量指标上取得了最好的性能,如表2所示。同时,它也给出了最好的可视化结果,如图5所示。结果表明,删除我们提出的模型的任何部分都会导致性能下降。

图5 .消融研究的定性结果。每个消融模型的基本事实和合成图像列在列中。

表2 .在全模型中对每个拟议成分进行定量消融。最后一行给出了最终模型的性能。在上述三行中,我们有意地从完整模型中排除了一个成分。详见第4.3节。
虚拟试戴和头部交换 Virtual Try-on and Head Swapping

图6 .在虚拟试戴上与其他先进方法的视觉比较。

表3 .在虚拟试穿和头部(身份)交换任务上,FID得分和用户研究与其他先进方法的比较。
受益于语义区域风格编码器,我们的模型还可以在无需进一步训练的情况下,通过交换风格特征(例如,上身转移、下身转移和头部交换)中特定语义区域的通道特征,实现基于参考图像的可控人物图像合成。我们将我们的方法与ADGAN 和PISE 进行了比较。直观对比见图6。我们观察到我们的模型可以重建目标部分并更忠实地保留其他剩余部分。此外,在转移下半身时,PISE无法将目标裤子转移给源人,会保留源人裤子的形状,只转移纹理。
为了更全面的比较,还进行了定量比较和用户研究。结果见表3。在用户研究中,我们为每个任务随机选择了40个由我们的方法和其他对比方法生成的结果,然后我们邀请了30个志愿者来选择最真实的结果。Jab为所有方法中被判定为最佳的图像所占百分比。
目标解析地图合成 Target parsing map synthesis
此外,为了更直观地理解我们的CASD块,我们在图1中进一步展示了预测的目标解析图。这表明,当给定源图像和各种目标姿态时,我们的模型不仅可以传输姿态,还可以合成目标解析图,尽管我们没有单独构建模型来实现这一点。我们在表4中列出了我们的方法和[ 8 ]对所有语义的预测之间的交并比( Intersection over Union,IoU )度量。对于主要语义,我们实现了比SPGNet更高的IoU [ 19 ]。注意,我们的模型在一个阶段中给出了最终的合成图像和目标解析图。合成的成对数据可以作为训练数据进行分割。
- Gong, K., Liang, X., Zhang, D., Shen, X., Lin, L.: Look into person: Self-supervised structure-sensitive learning and a new benchmark for human parsing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 932–940 (2017)
- Lv, Z., Li, X., Li, X., Li, F., Lin, T., He, D., Zuo, W.: Learning semantic person image generation by region-adaptive normalization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10806–10815 (2021)

表4 .在预测的目标解析图上将每类IoU与SPGNet进行对比。

图7 .失败案例由无法理解的服装(左)或姿势(右)引起。
局限性 Limitations
尽管我们的方法在大多数情况下产生了令人印象深刻的结果,但它仍然无法生成不可理解的服装和姿势。如图7所示,一件衬衫上的特定结无法生成,罕见姿势的人无法无缝合成。我们认为用更多种类的图像训练模型会缓解这个问题。我们认为用更多种类的图像训练模型会缓解这个问题。
结论 Conclusion
本文提出了一种用于单阶段可控人物图像合成任务的基于交叉注意力的风格分布块,具有较强的将源语义风格与目标姿态对齐的能力。基于交叉注意力的风格分布块主要由自注意力和交叉注意力组成,不仅能够准确地捕获源语义风格,而且能够将其精确地对齐到目标姿态。为了达到更清晰的目的,提出了AMCE损失,通过目标解析图来约束交叉注意力中的注意力矩阵。大量的实验和消融研究表明了我们模型的令人满意的性能,以及其组成部分的有效性。最后,我们表明我们的模型可以很容易地应用于虚拟试穿和头部(身份)交换任务。
附录 Appendix
A 网络结构 Network architectures
在这一部分,我们提供了网络结构的细节。表5、表6分别为编码器E、生成器G的网络结构。在Conv和Residual Block中,F、K和S分别表示输出维度、卷积核大小和步长。IN和LN分别表示实例归一化和图层归一化。

表5 .编码器E的结构。在E中,我们将$I^i_s$放入预训练的VGG19网络中,并将对应层的特征作为边分支,与主分支拼接在一起。注意,我们仅以一种来源风格$I^i_s$为例,其中i = 1,2,· · ·,8为语义索引。最后所有的$I^i_s$拼凑在一起。

表6 .生成器G的结构。在AdaIN ResBlocks和AFN ResBlocks中,括号中的内容作为边分支影响主分支。
B 与最先进的技术比较 Comparisons with the state-of-the-arts

图8 .我们的方法与其他先进方法的定性比较。目标真值和每个模型的合成结果以行列出。
在图8中,我们提供了我们的方法和其他最先进的( e.g. PATN 、GFLA 、ADGAN 、PISE 、SPGNet 、CoCosNet )之间的额外的定性比较。结果表明,我们的方法能够生成与目标更加一致的外观和姿态。
C对生成的解析图进行可视化 Visualization of the generated parsing maps

图9。在给定源图像的情况下,我们的模型能够根据需要进行位姿传递。展示了生成的目标解析图的合成人物和可视化。
我们还提供了图9中生成的解析图的更多可视化结果。可见,交叉注意力矩阵能够准确预测目标解析图,且不受姿态和视角变化的影响,表明了所提出的基于交叉注意力的风格分布模块的有效性。
D虚拟试穿结果 Results of virtual try-on

图10 .给定源图像和参考图像,我们的模型能够执行虚拟试穿任务。上半部分为试穿上衣的结果,下半部分为试穿裤子的结果。
通过交换风格特征中特定语义区域的通道特征,我们的模型可以实现虚拟试穿任务。虚拟试戴的其他例子如图10所示。